En el mundo digital actual, la velocidad lo es todo. Tus usuarios esperan respuestas instantáneas, y si tu API no las proporciona, corres el riesgo de perderlos. Una API lenta no solo frustra a los desarrolladores que la consumen, sino que también degrada la experiencia del usuario final, impacta negativamente el SEO, y puede resultar en pérdidas significativas para tu negocio. La latencia, el rendimiento deficiente y los tiempos de espera prolongados son problemas comunes que plagan muchas APIs, pero a menudo, la causa raíz se encuentra en unos pocos cuellos de botella predecibles.
Detectar y resolver estos problemas no tiene por qué ser una tarea desalentadora. De hecho, muchos de los problemas de rendimiento más comunes se pueden abordar con mejoras prácticas que puedes implementar hoy mismo. En este artículo, desglosaremos los tres cuellos de botella más frecuentes que hacen que las APIs sean lentas y, lo que es más importante, te proporcionaremos soluciones accionables para optimizar el rendimiento de tu API de inmediato. Prepárate para transformar tu API de tortuga a liebre, mejorando la satisfacción del usuario y la eficiencia de tu sistema.
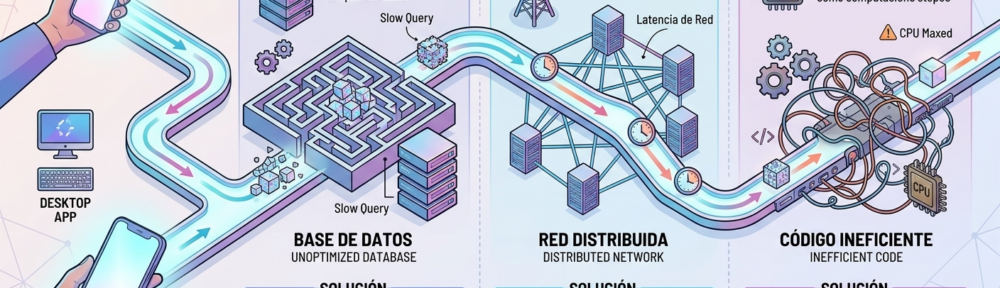
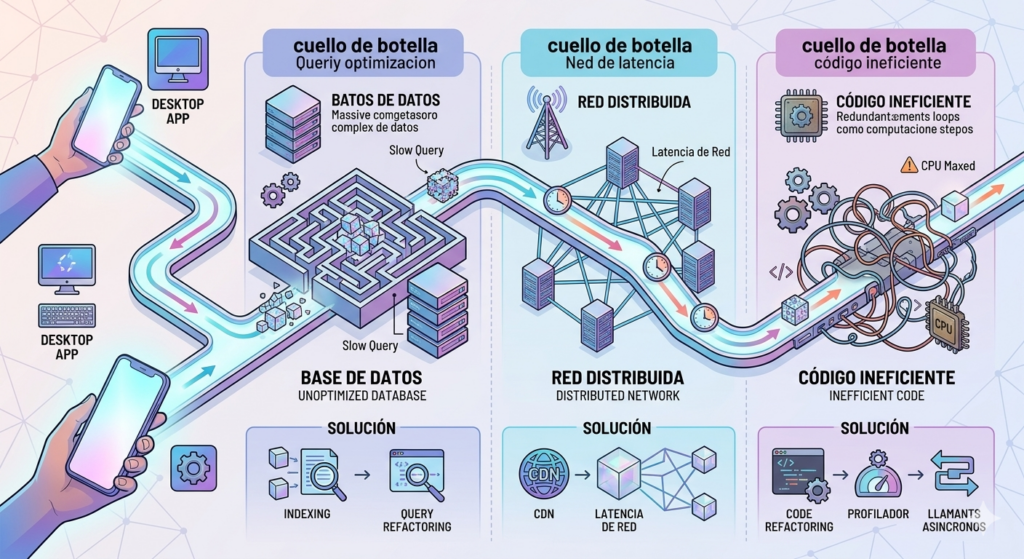
1. Consultas Lentas a la Base de Datos
La base de datos es el corazón de la mayoría de las aplicaciones. Si el acceso a estos datos es lento, toda la API se ralentizará. Las consultas a la base de datos son uno de los cuellos de botella más comunes y, a menudo, los más impactantes en el rendimiento de una API.
¿Por qué la base de datos es un cuello de botella?
- Consultas ineficientes: Consultas mal escritas que escanean tablas enteras en lugar de usar índices, o que realizan uniones (JOINs) complejas y costosas.
- Problema N+1: Un error común donde la aplicación realiza una consulta inicial para obtener una lista de elementos y luego, para cada elemento de la lista, ejecuta una consulta adicional para obtener detalles relacionados. Esto convierte una sola operación en N+1 operaciones.
- Falta de índices: Los índices son cruciales para la velocidad de búsqueda y recuperación. Sin ellos, la base de datos debe escanear registros secuencialmente para encontrar los datos, lo cual es ineficiente en grandes volúmenes.
- Volumen de datos: A medida que la base de datos crece, las consultas no optimizadas se vuelven exponencialmente más lentas.
Cómo diagnosticarlo:
- Herramientas de monitoreo de rendimiento de aplicaciones (APM): Soluciones como Datadog, New Relic o Dynatrace pueden perfilar automáticamente las consultas a la base de datos, mostrando cuáles son las más lentas y dónde se originan.
- Registros de consultas lentas de la base de datos: La mayoría de los sistemas de gestión de bases de datos (SQL Server, MySQL, PostgreSQL, MongoDB) tienen una funcionalidad para registrar consultas que exceden un cierto umbral de tiempo.
- Profiling manual: Utiliza herramientas específicas de la base de datos (como
EXPLAINen SQL) para analizar el plan de ejecución de consultas individuales.
Cómo solucionarlo hoy mismo:
- Añade Índices: Identifica las columnas utilizadas en las cláusulas
WHERE,ORDER BY,GROUP BYyJOINy asegúrate de que tengan índices adecuados. Esta es a menudo la solución más rápida y efectiva. - Optimiza Consultas N+1: Utiliza la carga ansiosa (eager loading) de tu ORM (Object-Relational Mapper) o construye consultas JOINs explícitas para recuperar todos los datos relacionados en una sola consulta. Por ejemplo, en vez de:
SELECT * FROM orders; -- Luego, en un bucle para cada orden: SELECT * FROM order_items WHERE order_id = ?;Haz:
SELECT orders.*, order_items.* FROM orders JOIN order_items ON orders.id = order_items.order_id; - Caché a nivel de aplicación o base de datos: Para datos que cambian con poca frecuencia pero se acceden a menudo, implementa una capa de caché (por ejemplo, con Redis o Memcached). Esto reduce la necesidad de golpear la base de datos en cada solicitud.
- *Evita `SELECT `:** En lugar de seleccionar todas las columnas, especifica solo las columnas que realmente necesitas. Esto reduce el tamaño del conjunto de resultados y la carga de red.
- Revisa tu ORM: Aunque los ORMs son convenientes, a veces pueden generar consultas ineficientes. Aprende a usarlos para generar consultas optimizadas o, para consultas complejas, recurre a SQL nativo.
2. Llamadas a Servicios Externos y Latencia de Red
Las APIs modernas rara vez operan de forma aislada. A menudo dependen de servicios externos, como pasarelas de pago, servicios de terceros para envío de correos, APIs de redes sociales o incluso microservicios internos. Cada llamada a un servicio externo introduce su propia latencia y posibles puntos de falla.
¿Por qué son un cuello de botella?
- Dependencia externa: No tienes control sobre el rendimiento del servicio externo. Si el servicio de terceros es lento, tu API también lo será.
- Latencia de red: Cada solicitud y respuesta a un servicio externo implica un viaje a través de la red, añadiendo un tiempo inherente de ida y vuelta (round-trip time).
- Bloqueo de ejecución: Si tu API espera sincrónicamente la respuesta de un servicio externo, el hilo de ejecución se bloquea, deteniendo otras operaciones.
- Límites de tasa (Rate Limiting): Algunos servicios externos imponen límites en el número de solicitudes por unidad de tiempo, lo que puede causar retrasos si se exceden.
Cómo diagnosticarlo:
- APM con trazabilidad distribuida: Las herramientas APM que soportan la trazabilidad distribuida pueden seguir una solicitud a través de múltiples servicios, identificando cuánto tiempo se dedica a cada llamada externa.
- Registros de la aplicación: Registra el tiempo que tardan las llamadas a servicios externos para identificar patrones o servicios particularmente lentos.
- Monitoreo sintético: Configura monitores que prueben la disponibilidad y el rendimiento de los servicios externos de forma regular.
Cómo solucionarlo hoy mismo:
- Caché de respuestas externas: Para datos de servicios externos que no cambian con frecuencia (por ejemplo, datos de perfiles de usuario de redes sociales, tipos de cambio que se actualizan cada hora), almacena en caché las respuestas durante un período.
- Llamadas asíncronas y colas de mensajes: Si la respuesta del servicio externo no es necesaria inmediatamente para la respuesta de la API, procesa la llamada de forma asíncrona. Envía la tarea a una cola de mensajes (por ejemplo, RabbitMQ, Kafka, SQS) y deja que un trabajador de fondo la procese.
- Agrupación (Batching) de solicitudes: Si un servicio externo permite agrupar múltiples solicitudes en una sola (por ejemplo, enviar un array de IDs para obtener múltiples recursos), úsalo para reducir el número de viajes de ida y vuelta.
- Implementa Timeouts y Reintentos con Backoff: Configura tiempos de espera razonables para las llamadas externas. Si un servicio tarda demasiado, tu API debería fallar rápidamente en lugar de esperar indefinidamente. Para fallos transitorios, implementa una estrategia de reintentos con backoff exponencial.
- Circuit Breakers (Interruptores de Circuito): Implementa el patrón Circuit Breaker para evitar enviar continuamente solicitudes a un servicio externo que está fallando. Esto permite que el servicio externo se recupere y evita que tu API se sature con errores.
- Elige proveedores más cercanos o CDN: Si el problema es la latencia geográfica, considera usar proveedores de servicios externos con servidores más cercanos a tu infraestructura o que utilicen Redes de Entrega de Contenido (CDN).
3. Código de Aplicación Ineficiente y Procesamiento Excesivo
A veces, la lentitud no se debe a la base de datos ni a los servicios externos, sino al propio código de la aplicación. Cálculos complejos, bucles ineficientes, manipulación de grandes conjuntos de datos en memoria o la falta de optimización del código pueden consumir recursos de CPU y memoria, ralentizando la API.
¿Por qué es un cuello de botella?
- Algoritmos ineficientes: El uso de algoritmos con alta complejidad temporal (por ejemplo, O(n^2) o peor) en grandes conjuntos de datos.
- Procesamiento innecesario: Realizar cálculos, transformaciones o filtrados de datos que no son estrictamente necesarios para la respuesta de la API.
- Grandes cargas útiles (Payloads): Recuperar o generar respuestas con una cantidad excesiva de datos, incluso si el cliente solo necesita una pequeña parte.
- Bloqueo de CPU: Tareas computacionalmente intensivas que monopolizan el hilo de ejecución, impidiendo que otras solicitudes sean procesadas.
- Problemas de concurrencia: Manejo inadecuado de múltiples solicitudes, lo que lleva a bloqueos (deadlocks) o contención de recursos.
Cómo diagnosticarlo:
- Profiler de código: Herramientas de perfilado específicas del lenguaje (por ejemplo, cProfile para Python, pprof para Go, JProfiler para Java) pueden identificar qué funciones y métodos consumen la mayor parte del tiempo de CPU.
- APM con seguimiento de funciones: Muchas herramientas APM pueden desglosar el tiempo de ejecución de una solicitud por componentes de código, mostrando dónde se dedica el tiempo dentro de tu aplicación.
- Pruebas de carga: Simular un alto volumen de tráfico puede revelar dónde el código se vuelve ineficiente bajo estrés.
- Monitoreo de recursos: Observa el uso de CPU y memoria de tus instancias de API. Un uso constantemente alto sin picos obvios de base de datos o red puede indicar problemas de código.
Cómo solucionarlo hoy mismo:
- Optimiza Algoritmos y Estructuras de Datos: Revisa tu código en busca de bucles anidados innecesarios o manipulaciones de datos que puedan simplificarse. Utiliza estructuras de datos adecuadas para el problema (por ejemplo, hash maps para búsquedas rápidas en lugar de arrays).
- Minimiza la Carga Útil (Payload): Implementa el filtrado de campos, la paginación y la limitación en tus endpoints. Permite que los clientes especifiquen qué campos necesitan o cuántos elementos por página desean, en lugar de enviar siempre el conjunto completo de datos.
- Offload de Tareas Pesadas: Mueve las tareas computacionalmente intensivas o de larga duración a procesos en segundo plano (workers) que no bloqueen la respuesta de la API. Utiliza colas de mensajes para comunicarte con estos trabajadores.
- Compresión de Respuestas: Habilita la compresión GZIP o Brotli en tu servidor web (Nginx, Apache) para reducir el tamaño de las respuestas enviadas al cliente, disminuyendo el tiempo de transferencia de red.
- Caché en Memoria (In-Memory Cache): Para resultados de cálculos costosos que se solicitan a menudo, almacena en caché el resultado directamente en la memoria de la aplicación.
- Control de Concurrencia: Asegúrate de que el acceso a recursos compartidos (como contadores, cachés internos) esté sincronizado correctamente para evitar condiciones de carrera y bloqueos.
- Actualiza tus dependencias: A veces, las librerías o frameworks más nuevos vienen con mejoras de rendimiento significativas. Mantener tus dependencias actualizadas puede traer beneficios inesperados.
Conclusión
La lentitud de una API es un síntoma, no una enfermedad. Al comprender los cuellos de botella más comunes —consultas lentas a la base de datos, dependencia de servicios externos y código de aplicación ineficiente— y aplicar las soluciones que hemos detallado, puedes mejorar drásticamente el rendimiento de tu API. Recuerda que la optimización es un proceso continuo.
Empieza hoy mismo utilizando herramientas de monitoreo para identificar el origen de la lentitud, prioriza las mejoras que tengan el mayor impacto y mide los resultados. Tus usuarios y tu negocio te lo agradecerán. Una API rápida no es un lujo, es una necesidad en el panorama digital actual. ¿Estás listo para acelerar la tuya?